In an earlier article I discussed how to determine what metrics you might want to watch as part of cluster monitoring, as well as the frequency at which you might want to monitor them. This process answers questions about what information you really want to know about the cluster and makes you think a bit more about monitoring before jumping in immediately and starting to code. The key result is a set of processes and system states you would like to measure to gain insight into what the cluster is doing.
In the previous article, I particularly looked at the frequency of monitoring: Does it make sense to measure the 15-minute node load average every few seconds? If the application takes 12 hours to run, do you need to measure the CPU load every two to three seconds? The main result of frequent monitoring is a large amount of data that may or may not be useful (more on that in a future article). However, if your application runs in less than 15 minutes, then perhaps you’d like to measure CPU usage a little more frequently. The point is that you should think about how frequently you need or want to measure your metrics before you blindly assume you want everything measured every second.
After determining the frequency at which to measure processes, the next step is to write code that implements or measures the processes of interest. The focus will be on writing code that collects data on an individual node basis. In this article, I won’t discuss how to take all of the information from the nodes and make use of them, and I won’t discuss how to create alerts on the basis of these metrics that tell you about a potential problem, although I’ll discuss these topics in future articles.
Before I think about coding, I look at the tools I normally use when administering servers because I am familiar with them and I understand their output. If that isn’t possible, I look for other tools that can provide the metrics I want. If that fails, I resort to writing my own code. However, in some cases, I write code because I will better understand what is being measuring and precisely how. Moreover, I have the flexibility of changing the code I write.
A good place to start when looking at what other people have written is collections or toolkits for systems monitoring. A non-exhaustive list of general toolkits that people use to monitor system processes includes:
- collectl
- sysstat (sar), with ksar to plot metrics
- Monitorix
- Munin
- Cacti
- Ganglia
- Zabbix
- Zenoss
- Observium
- GKrellM
Some of these programs gather a great deal of information and create plots (visualization) for individual nodes (e.g., collectl or sar+ksar). Others gather metrics for clusters (e.g., Ganglia or Cacti), and some come with plotting tools built-in using the RRDtool database. Some tools are specifically for performance profiling, not general monitoring, although you can easily extend them past their default features into monitoring by writing your own code, which leads directly into my theme for this article: writing monitoring code.
In this article, I discuss a few classes of metrics as well as simple code that can implement these metrics. I’ll use Python because I know it well enough and because many useful Python add-on tools already exist. Feel free to code in any language you like, but I recommend you stay fairly generic and select an interpreted language, such as Python, Perl, or even Bash (shell scripting), because it makes integrating your code into a monitoring framework much easier. The three coding approaches I present use:
- Built-in Python modules such as the os module, which is a portable way of interacting with the operating system and includes a number of useful monitoring functions.
- Outside libraries that are not part of the standard Python distribution but have Python interfaces. In this case, I only use one, psutil, which builds very easily and has many easy-to-use monitoring functions.
- Linux resources for virtual filesystems. Two virtual filesystems in Linux, procfs and sysfs, collect data on system processes and devices and drivers. Understanding and parsing /proc and /sys provides useful monitoring information.
Ultimately, I will cover five classes of metrics – processor, memory, process, network, and disk – but in this article, I will look at processor and memory metrics. For each metric, I present a simple script or two; virtually all of the scripts create more than one metric.
Processor Metrics
As I mentioned in the first article, two types of processor metrics likely are useful: The first measures processor usage for the node as a whole, and the second metric is associated with each core. Each metric requires appropriate measures and code.
The easiest way to develop processor monitoring metrics is to use the information closest at hand. The most obvious processor metric is the system load as measured by uptime. According to the man pages:
uptime gives a one line display of the following information. The current time, how long the system has been running, how many users are currently logged on, and the system load averages for the past 1, 5, and 15 minutes.
Uptime gives you a “load” factor for all processors; that is, if a node has eight cores, you would like the load to be 8.0 or less. However, if you’re running applications that use more processing power than is available, the load can go higher than 8.0, resulting in time slicing.
In addition to uptime, administrators use top, which contains some of the same information as uptime and more. From the man page:
The top program provides a dynamic real-time view of a running system. It can display system summary information as well as a list of processes or threads currently being managed by the Linux kernel. The types of system summary information shown and the types, order and size of information displayed for processes are all user configurable and that configuration can be made persistent across restarts.
Top provides the basic load on the system in the same fashion as Uptime, but it also provides processor usage as a percentage for various aspects of processor usage. Furthermore, it also presents information about memory usage and swap space. You also get a sorted list of all of the processes running on the system.
Is it possible to write a script that reproduces the information provided by uptime and top? The answer is yes, and it’s not too difficult with a little help. In the following sections, I present Python scripts that gather this information using some of the approaches I previously mentioned (built-in libraries, outside libraries, or parsing the virtual filesystems).
Uptime-like Processor Information
Python comes with a nice module called os that has many operating system-independent functions (methods) that can be used to interact with the OS. One of them, os.getloadavg, allows you to get the same information that uptime provides (load averages for 1, 5, and 15 minutes). The resulting Python script is fairly simple (Listing 1).
Listing 1: Uptime-like Information
#!/usr/bin/python try: import os except ImportError: print "Cannot import os module - this is needed for this code."; print "Exiting..." sys.exit(); try: import time except ImportError: print "Cannot import time module - this is needed for this code."; print "Exiting..." sys.exit(); # =================== # Main Python section # =================== if __name__ == '__main__': load_avg = os.getloadavg() print "load average: %.2f, %.2f, %.2f" % (load_avg[0], load_avg[1], load_avg[2]); # end main
This simple code prints out the 1, 5, and 15-minute load averages. The output from the function is a tuple, and you can break out the individual loads as I did (load_avg[0], load_avg[1], and load_avg[2]). Note that I added some code to the beginning of the script to make sure the modules were actually there before the code would run. (I like wearing a belt and a pair of suspenders.) I apologize if my code isn’t very Pythonic, but I hope you get the idea.
The loads are pretty low on my desktop, so the following sample output from the code is fairly uninteresting:
[laytonjb@home4 2]$ ./test1.py load average: 0.43, 0.43, 0.43
I know how this code works on Linux, but I don’t know how it works on Windows or other Unix operating systems. If you want to gather monitoring statistics on those platforms, I suggest testing the code or searching for cross-platform techniques that give you the same information.
Top-like Processor Information
Top presents more information than Uptime,so reproducing that information might be more difficult. Recall that top contains processor, memory, and process information, but for this section of the article, I’m going to focus on the processor metrics (the memory and swap aspects of top will be covered in the Memory Monitoring section of this article). Specifically, I will gather the following processor statistics in percent time:
- User CPU
- Nice CPU
- System CPU
- Idle CPU
- IO Wait CPU
- IRQ Servicing CPU
- Soft IRQ CPU
- Steal CPU
- Guest CPU (Top does not normally provide this.)
Notice that top doesn’t report the CPU time percentage spent for guest OSs (think virtualization). I’d like to start collecting that information since virtualizing some HPC systems could be a big win for many HPC sites.
With these nine metrics, I want to gather the statistics both on a per-server basis and a per-core basis. The biggest reason is that the information on a per-server basis will give me a quick glance of the server as a whole. The same information on a per-CPU basis will give me a better idea of what the cores are doing, which can be especially important if the nodes are shared. Fortunately, a nice library called psutil provides cross-platform CPU, memory, disk, and network statistics. Currently it supports Linux, Windows, OS X, FreeBSD, and Solaris for both 32- and 64-bit systems. The library has a very useful Python module that I plan to exploit.
I built the library very simply with the command:
[root@home4 ~]# python setup.py
Doing this as root will build and install the library to match your system.
Two functions in psutil I’ll be using for CPU metrics are cpu_percent(), which returns a summary of CPU usage as a single percentage for the entire server or each core (user controllable), and cpu_times_percent(), which returns the details of CPU usage for the entire server or each core (also user controllable). The percent CPU details returned are:
- user
- system
- idle
- nice (Unix)
- iowait (Linux)
- irq (Linux, FreeBSD)
- softirq (Linux)
- steal (Linux ≥ 2.6.11)
- guest (Linux ≥ 2.6.24)
- guest_nice (Linux ≥ 3.2.0)
The Python code for gathering CPU statistics isn’t too difficult: I include both the “summary” CPU percent load and the “details” of the CPU load in a single script, so you can see the differences (Listing 2). I also use a 0.5-second interval to capture statistics to compute the “rate” statistics. On my desktop, if I use anything quicker (i.e., <0.5 seconds), I don’t always see the load vary much.
Listing 2: Top-like Information
#!/usr/bin/python try: import psutil except ImportError: print "Cannot import psutil module - this is needed for this application."; print "Exiting..." sys.exit(); style="margin:0px auto" # =================== # Main Python section # =================== if __name__ == '__main__': # Current system-wide CPU utilization as a percentage # --------------------------------------------------- # Server as a whole: percs = psutil.cpu_percent(interval=0.5, percpu=False) print " CPU ALL: ",percs," %"; # Individual CPUs percs = psutil.cpu_percent(interval=0.5, percpu=True) for cpu_num, perc in enumerate(percs): print " CPU%-2s %5s%% " % (cpu_num, perc); # end for # Details on Current system-wide CPU utilziation as a percentage # -------------------------------------------------------------- # Server as a whole perc = psutil.cpu_times_percent(interval=0.5, percpu=False) print " CPU ALL:"; str1 = " user: %5s%% nice: %5s%%" % (perc.user, perc.nice); str2 = " system: %5s%% idle: %5s%% " % (perc.system, perc.idle); str3 = " iowait: %5s%% irq: %5s%% " % (perc.iowait, perc.irq ); str4 = " softirq: %5s%% steal: %5s%% " % (perc.softirq, perc.steal); str5 = " guest: %5s%% " % (perc.guest); print str1 print str2 print str3 print str4 print str5; # Individual CPUs percs = psutil.cpu_times_percent(interval=0.5, percpu=True) for cpu_num, perc in enumerate(percs): print " CPU%-2s" % (cpu_num); str1 = " user: %5s%% nice: %5s%%" % (perc.user, perc.nice); str2 = " system: %5s%% idle: %5s%% " % (perc.system, perc.idle); str3 = " iowait: %5s%% irq: %5s%% " % (perc.iowait, perc.irq ); str4 = " softirq: %5s%% steal: %5s%% " % (perc.softirq, perc.steal); str5 = " guest: %5s%% " % (perc.guest); print str1 print str2 print str3 print str4 print str5; # end for # end if
The output format is intentional, so the width of the script is fairly small (easier for publication). Otherwise, I would have used the print statement to output a single line. However, I will be modifying these scripts when I integrate them into a monitoring framework. Listing 3 is sample output from the code.
Listing 3: Top-like Output
[laytonjb@home4 4]$ ./cpu_test2.py CPU ALL: 1.0 % CPU0 4.1% CPU1 2.0% CPU2 0.0% CPU3 0.0% CPU4 0.0% CPU5 0.0% CPU6 0.0% CPU7 2.0% CPU ALL: user: 0.7% nice: 0.0% system: 0.2% idle: 99.0% iowait: 0.0% irq: 0.0% softirq: 0.0% steal: 0.0% guest: 0.0% CPU0 user: 4.0% nice: 0.0% system: 2.0% idle: 94.0% iowait: 0.0% irq: 0.0% softirq: 0.0% steal: 0.0% guest: 0.0% CPU1 user: 0.0% nice: 0.0% system: 2.0% idle: 98.0% iowait: 0.0% irq: 0.0% softirq: 0.0% steal: 0.0% guest: 0.0% CPU2 user: 0.0% nice: 0.0% system: 0.0% idle: 100.0% iowait: 0.0% irq: 0.0% softirq: 0.0% steal: 0.0% guest: 0.0% CPU3 user: 0.0% nice: 0.0% system: 0.0% idle: 100.0% iowait: 0.0% irq: 0.0% softirq: 0.0% steal: 0.0% guest: 0.0% CPU4 user: 0.0% nice: 0.0% system: 0.0% idle: 100.0% iowait: 0.0% irq: 0.0% softirq: 0.0% steal: 0.0% guest: 0.0% CPU5 user: 0.0% nice: 0.0% system: 0.0% idle: 100.0% iowait: 0.0% irq: 0.0% softirq: 0.0% steal: 0.0% guest: 0.0% CPU6 user: 0.0% nice: 0.0% system: 0.0% idle: 100.0% iowait: 0.0% irq: 0.0% softirq: 0.0% steal: 0.0% guest: 0.0% CPU7 user: 0.0% nice: 0.0% system: 0.0% idle: 100.0% iowait: 0.0% irq: 0.0% softirq: 0.0% steal: 0.0% guest: 0.0%
I added the extra lines in the output to make the column narrow enough for publication (even the web abhors a long line of text). Notice that most of my cores are idle (idle percentage is 100%), with only CPU0 executing user applications – but not much.
Memory Metrics
Memory usage is tricky in Linux. Linux uses free memory for buffers and caching when it can, by which virtually all applications benefit. Therefore, all memory appears to be used, even though the kernel frees it when an application needs it. This is compounded by the use of shared libraries that reduces overall memory usage (a good thing) but also makes it more difficult to estimate how much memory an application is actually using.
In general, though, I’m interested in the total amount of memory used by applications, including shared libraries. I understand that some of these are likely system applications, but in the HPC world, people generally keep this to a minimum. Basically, I need tools that monitor memory usage as well as swap usage – I still tend to think of swap space as “memory,” because the kernel can stash pages there; therefore, the metrics I’m interested in monitoring are:
- Total memory usage on a node
- Total memory usage on a node by all non-root users (and root)
- Total memory usage for specific users
- Swap space used
Details of memory usage, such as what the kernel is using, what it is using for buffers or caching, and so on, would also be useful. Moreover, getting these statistics for all non-root users, as well as on a per-user basis (considering root a user in this case), would be nice. For this task, I’ll present two memory and swap usage tools: ps_mem and psutil.
ps_mem
The ps_mem tool is a Python script for reporting the core memory being used (not swap space). The tool reports the amount of private memory being used (i.e., non-shared) and the shared amount of memory for each process. Note that you have to run the tool as root, so be sure you address any security issues. Listing 4 shows a subset of the output when I run it on my desktop (some output has been removed for the sake of brevity).
Listing 4: System Information from ps_mem
[root@home4 1]# ./ps_mem.py Private + Shared = RAM used Program 84.0 KiB + 12.5 KiB = 96.5 KiB kwrapper4 128.0 KiB + 25.5 KiB = 153.5 KiB acpid 152.0 KiB + 12.0 KiB = 164.0 KiB mcelog 152.0 KiB + 43.0 KiB = 195.0 KiB abrtd 164.0 KiB + 36.5 KiB = 200.5 KiB hald-addon-acpi 180.0 KiB + 24.0 KiB = 204.0 KiB xinit 160.0 KiB + 55.0 KiB = 215.0 KiB sh 188.0 KiB + 42.0 KiB = 230.0 KiB abrt-dump-oops 188.0 KiB + 45.5 KiB = 233.5 KiB hald-addon-input ... 22.9 MiB + 4.0 MiB = 26.9 MiB plasma-desktop 26.0 MiB + 5.7 MiB = 31.7 MiB konsole (3) 28.3 MiB + 4.4 MiB = 32.7 MiB kwin 41.0 MiB + 2.0 MiB = 43.0 MiB Xorg 146.9 MiB + 4.2 MiB = 151.0 MiB thunderbird 503.6 MiB + 5.0 MiB = 508.6 MiB firefox --------------------------------- 929.8 MiB =================================
The applications running on my desktop use a total of just under 1GiB of memory. Listing 5 shows the output from this tool for the memory usage of a particular user (again, the length of the output has been reduced for the sake of brevity).
Listing 5: User Information from ps_mem
[root@home4 1]# ./ps_mem.py -p $(pgrep -u laytonjb | paste -d, -s) Private + Shared = RAM used Program 84.0 KiB + 12.5 KiB = 96.5 KiB kwrapper4 180.0 KiB + 24.0 KiB = 204.0 KiB xinit 160.0 KiB + 55.0 KiB = 215.0 KiB sh 208.0 KiB + 29.0 KiB = 237.0 KiB gam_server 188.0 KiB + 62.0 KiB = 250.0 KiB startx 280.0 KiB + 27.5 KiB = 307.5 KiB dbus-launch 296.0 KiB + 27.5 KiB = 323.5 KiB gpg-agent 280.0 KiB + 64.5 KiB = 344.5 KiB startkde 348.0 KiB + 59.5 KiB = 407.5 KiB xsettings-kde ... 12.3 MiB + 2.2 MiB = 14.6 MiB gedit 22.9 MiB + 4.0 MiB = 26.9 MiB plasma-desktop 26.4 MiB + 5.7 MiB = 32.1 MiB konsole (3) 28.3 MiB + 4.4 MiB = 32.7 MiB kwin 147.9 MiB + 4.2 MiB = 152.1 MiB thunderbird 508.9 MiB + 5.0 MiB = 514.0 MiB firefox --------------------------------- 861.2 MiB =================================
By taking the difference between this output and the output for all processes, I discover that root is using about 68.6MiB of memory (private and swap) and the user is using 861.2MiB of memory. To confirm this, I use the command
./ps_mem.py -p $(pgrep -u root | paste -d, -s)
Note that if you try entering a user that doesn’t exist, the application will let you know (invalid user name: …).
With this script, you could discover what applications a user is running and what applications root is running on a given node. If you run the script and stash the output in a file or database, you could use this information to track down any problems that might pop up. For example, you could use it to find out what applications root is running on each node in the cluster, compare them, and look for differences (e.g., Why is a particular node running a particular application?). Over a period of time, you could find what additional applications root is running compared with when the system was first installed. Also, the information could reveal whether a user’s application is using a great deal of memory. You can correlate this with CPU usage to understand whether an application needs lots of CPU horsepower or lots of memory.
Sometimes I don’t want to see all of the memory usage details and would rather just have a sum total in a single line of output. I did a quick modification to ps_mem.py to do this (I changed the name to ps_mem2.py):
[root@home4 1]# ./ps_mem2.py 950.0 MiB
The changes I made are quite trivial, but for the sake of completeness Listing 6 shows the diff between the original file and the file I modified.
Listing 6: Memory Usage Diff
417,421c417,421
< for cmd in sorted_cmds:
< sys.stdout.write("%8sB + %8sB = %8sB\t%s\n" %
< (human(cmd[1]-shareds[cmd[0]]),
< human(shareds[cmd[0]]), human(cmd[1]),
< cmd_with_count(cmd[0], count[cmd[0]])))
---
> #for cmd in sorted_cmds:
> # sys.stdout.write("%8sB + %8sB = %8sB\t%s\n" %
> # (human(cmd[1]-shareds[cmd[0]]),
> # human(shareds[cmd[0]]), human(cmd[1]),
> # cmd_with_count(cmd[0], count[cmd[0]])))
423,424c423,425
< sys.stdout.write("%s\n%s%8sB\n%s\n" %
< ("-" * 33, " " * 24, human(total), "=" * 33))
---
> #sys.stdout.write("%s\n%s%8sB\n%s\n" %
> # ("-" * 33, " " * 24, human(total), "=" * 33))
> sys.stdout.write("%sB \n" % human(total));
449c450
< print_header()
---
> #print_header()
475a477
>
You can apply this patch to the file as
patch ps_mem.py <patch>
where <patch> is the name of the patch file.
psutil
In the previous script, I was able to obtain the amount of memory used as a total, by specific user, and even by application or certain applications. In addition to this information, it would be nice to have the summary view of memory and swap usage as top provides. In Figure 1, I’ve grabbed the topmost part of an exampletop output to illustrate the memory information to which I’m referring.
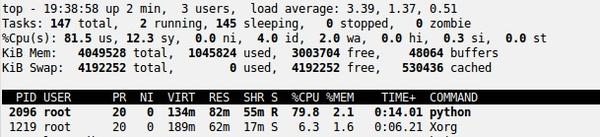 Figure 1: Snippet of Top output focusing on memory usage.
Figure 1: Snippet of Top output focusing on memory usage.
Notice that the output lists a number of memory usage statistics. Because I use top quite a bit and I’m comfortable with it, having a script that re-creates the same memory and swap usage would be helpful. Fortunately, a library I mentioned previously, psutil, has this capability.
Two psutil functions I’ll be using are virtual_memory(), which returns statistics about system memory usage, and swap_memory(), which returns system swap memory statistics. The Python code for gathering memory and swap statistics isn’t too difficult. Basically, you call both functions and then print out the information you need. I converted the data to megabytes (MiB or base 2 measurements) in the output to match the output oftop. The final script in Listing 7 is based on a BSD-style-licensed script by Giampaola Rodola, the author of psutil.
Listing 7: System Memory Script
#!/usr/bin/python
try:
import psutil
except ImportError:
print "Cannot import psutil module - this is needed for this application.";
print "Exiting..."
sys.exit();
try:
import re # Needed for regex
except ImportError:
print "Cannot import re module - this is needed for this application.";
print "Exiting..."
sys.exit();
#
# Routine to add commas to a float string
#
def commify3(amount):
amount = str(amount)
amount = amount[::-1]
amount = re.sub(r"(\d\d\d)(?=\d)(?!\d*\.)", r"\1,", amount)
return amount[::-1]
# end def commify3(amount):
# ===================
# Main Python section
# ===================
if __name__ == '__main__':
# memory usage:
mem = psutil.virtual_memory();
used = mem.total - mem.available;
a1 = str(int(used / 1024 / 1024)) + "M";
a2 = str(int(mem.total / 1024 / 1024)) + "M";
a3 = commify3(a1) + "/" + commify3(a2);
print ("Memory: %-10s (used)/(total)" % (a3) );
print ("Memory Total: %10sM" % (commify3(str(int(mem.total / 1024 / 1024)))) );
print ("Memory Available: %10sM" % (commify3(str(int(mem.available / 1024 / 1024)))) );
print "Memory Percent: %10s" % (str(mem.percent)),"%";
print ("Memory used: %10sM" % (commify3(str(int(mem.used / 1024 / 1024)))) );
print ("Memory free: %10sM" % (commify3(str(int(mem.free / 1024 / 1024)))) );
print ("Memory active: %10sM" % (commify3(str(int(mem.active / 1024 / 1024)))) );
print ("Memory inactive: %10sM" % (commify3(str(int(mem.inactive/ 1024 / 1024)))) );
print ("Memory buffers: %10sM" % (commify3(str(int(mem.buffers / 1024 / 1024)))) );
print ("Memory cached: %10sM" % (commify3(str(int(mem.cached / 1024 / 1024)))) );
# swap usage
swap = psutil.swap_memory();
a1 = str(int(swap.used / 1024 / 1024)) + "M";
a2 = str(int(swap.total / 1024 / 1024)) + "M";
a3 = commify3(a1) + "/" + commify3(a2);
print " ";
print ("Swap Space: %-10s (used)/(total)" % (a3) );
print ("Swap Total: %10sM" % (commify3(str(int(swap.total / 1024 / 1024)))) );
print ("Swap Used: %10sM" % (commify3(str(int(swap.used / 1024 / 1024)))) );
print ("Swap Free: %10sM" % (commify3(str(int(swap.free / 1024 / 1024)))) );
print "Swap Percentage: %10s" % (str(swap.percent)),"%";
print ("Swap sin: %10sM" % (commify3(str(int(swap.sin / 1024 / 1024)))) );
print ("Swap sout: %10sM" % (commify3(str(int(swap.sout / 1024 / 1024)))) );
# end if
The output from the script, which I ran on my desktop system, is shown in Listing 8.
Listing 8: System Memory Statistics
[laytonjb@home4 2]$ ./memory_test3.py Memory: 1,254M/32,042M (used)/(total) Memory Total: 32,042M Memory Available: 30,788M Memory Percent: 3.9 % Memory used: 2,057M Memory free: 29,984M Memory active: 1,051M Memory inactive: 588M Memory buffers: 222M Memory cached: 581M Swap Space: 0M/1,939M (used)/(total) Swap Total: 1,939M Swap Used: 0M Swap Free: 1,939M Swap Percentage: 0.0 % Swap sin: 0M Swap sout: 0M
The script can be modified easily to return the desired metric or metrics you want. Note that I printed each metric on its own line so that the script is more appropriate for publication.
In this piece, I looked at monitoring processor and memory activity. Next time, I’ll look at process, network, and disk metrics.
No comments:
Post a Comment